



Next: Transducer characteristics
Up: Talker / listener descriptors
Previous: General (demographic) descriptors
Task specific descriptors we define to be such that they directly describe the ability of a subject to perform a specific task. For example in listening tests it is crucial to check whether the experimentee is able to hear at all.
Since certain diseases like inflammation of the vocal cords are
known to potentially harm or at least influence the voice permanently,
we recommend asking for any related medical records.
Voice relevant habits we consider to be smoking, drinking
(cf. Section 3.5.2), and whether and to
what extent a subject has received voice training
or is accustomed to professional public speaking.
Moreover, one should check
whether a talker practises regular singing for either private or professional
reasons, and how much.
With anatomical talker descriptors, we distinguish between descriptors
derived from the subject's laryngeal behaviour and miscellaneous
descriptors. These types of descriptor are not mutually exclusive, i.e. a
laryngeal feature might well be explained in terms of jitter , shimmer , or
glottal-to-noise excitation and vice versa.
The difference is that a close look at the laryngeal properties of voice
necessitates the use of special pitch determination instruments
(cf. Section 8.4.2), whereas the other descriptors rely on the
analysis of the microphone time signal.
A perceptual classification based on listening might be sufficient,
as long as the classification is performed consistently by the same judge(s)
on the entire population.
But there exists no such thing as an absolute and generally accepted scale
for the quantisation of voice quality.
The following explanations on how to qualify a voice are partly based on a
signal output by a so-called laryngograph
(cf. Section 8.4.2).
This signal, which is proportional
to the electrical impedance of the larynx (i.e. the opening/closure
of the glottis), is referred to as Lx;
Fx denotes the fundamental frequency (a direct derivative
of Lx), and Cx stands for the scatterplot of 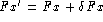 over the fundamental frequency (Fx). The latter represents a measure of the
variance of the fundamental frequency as a
function of the fundamental frequency.
over the fundamental frequency (Fx). The latter represents a measure of the
variance of the fundamental frequency as a
function of the fundamental frequency.
- Breathy Voice:
- A breathy voice results from slow,
sometimes incomplete closure of the vocal folds during the laryngeal
cycle. It is more often found in women than in men. The auditory impression
is that of a ``gentle'' voice, which in women sometimes reaches the point of
sounding ``whispery''.
A more sinusoidal shape of the Lx signal, as well as a lower closed/open
phase ratio calculated from it, are an indicator of breathy
voice . Acoustically, the zero-crossing rate in the 3-4kHz band during the voiced sections of an utterance is a measure of accompanying glottal friction . A further measure is the relative strength of the first and second harmonics (there being a step-down from the first to the second rather than an equal slope).
- Harsh Voice:
- This is the converse of a breathy
voice , and is more often found in men. It results, probably, from a very
fast closing gesture, and a high closed/open phase ratio . It is the sort of
voice that ``carries'' well in voice babble.
As might be expected by its converse relation to breathy voice , the more vertical closing phase of the Lx
wave and the
higher close/open phase ratio indicates a harsher
voice . Acoustically, the absence of the step-down from the first to the second harmonic and an overall flatter spectrum are characteristic of the voice quality.
- Creaky Voice:
- This is the result of irregular laryngeal vibrations,
often with a cycle of ``normal'' duration being followed by a cycle of roughly
twice the normal duration. It is found in both men and women. In some
speakers it occurs at particular parts of an intonation contour, typically
at the end of a phrase, when the voice sinks to the bottom of its range.
Irregular laryngeal vibrations are clearly visible in the Lx, and the Fx
distribution reveals a clear secondary mode about one octave below the main
mode. There are usually also points on the Cx scatterplot to either side of
the main diagonal at the lower end of the speaker's frequency
range.
- Hoarse Voice:
- This adjective is often given to a
mixture of laryngeal irregularity with breathiness . In everyday terms it is
the sort of voice that makes you think the speaker has been shouting a lot.
The combination of laryngeal irregularity and glottal friction in this voice
quality means that it is open to both laryngographic and acoustic
representation. The points to the side of the main diagonal of the Cx plot
usually spread along the whole of the speaker's range. Acoustically, a similar
zero-crossing measure can be used as for breathy voice . In addition, however,
the irregularity is clearly visible on a spectrogram.
It is currently impossible to give an all-embracing
compendium on voice descriptors. To this end, we restrict ourselves to those
we consider to be most common:
- Vocal tract size:
- It is generally agreed that body size correlates with
vocal tract size. However, observation of head size relative to body size is
a further criterion. We recommend logging such personal data,
i.e. height and weight and head perimeter of all subjects.
First and third-formant averages over a given utterance, spoken by persons with the same regional accent , can be used as an indicator of relative vocal-tract length.
- Jitter and Shimmer:
- Jitter and
shimmer are measures of the average perturbation of
someone's fundamental frequency and
of its magnitude, respectively. They are given by the formula:
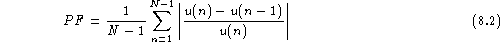
where u(n) denotes either the length of the observed excitation period
(jitter) or the energy in the period (shimmer) . Details on how to extract a
value for u(n) may be found in [Kasuya et al. (1993)] and [Michaelis & Strube (1995)].
Both measures mutually correlate to a high degree and have to be expected to
have high values in creaky as well as in hoarse voices
(see above).
- Glottal-to-Noise Excitation Parameter:
-
The glottal-to-noise excitation
parameter (GNE parameter) gives a figure of whether vocal excitation is
mainly due to glottal vibration (GNE = 1) or rather turbulent noise
(GNE = 0).
Since it is a measure of harshness it exhibits high values in harsh voices and
it will be found to be small in breathy and hoarse voices.
For further details
on this parameter consult [Michaelis & Strube (1995)].
This can be quantified by average word length for a number of agreed
isolated words. In continuous speech, average duration of (underlying) syllables in a
given utterance, excluding pauses, may serve. This allows for a rate measure
which excludes consideration of articulatory precision. At the same time the
minimum and maximum duration of the syllables can be recorded to establish
a measure of the dynamics of the rate of articulation.
It is difficult to define this in objective terms, and possibly there will be
disagreement in selecting speakers, except for extreme cases. Note
that this is not necessarily the same as speaking slow or fast, though the two
dimensions may covary among the same speakers. Though it has not been
investigated experimentally, we can assume in the first instance that the
impression of precise articulation has to do with the consistent avoidance of
frication for stops , and not producing fricatives as approximants,
not eliding
or slurring unstressed syllables very much. These are undoubtedly properties
that are of interest with respect to recogniser assessment.
In contrast to the rate of articulation, this measure should be based on the average duration of actually realised syllables .
Elided syllables, which contribute to the rate measure, would therefore be ignored.
Though the fundamental frequency in principle is a function of the subject's
anatomical data, it is modulated in both
directions by intonation, tone and accentuation. The dynamics are constituted by the
maximum and the minimum frequency observed in an agreed set of utterances.
The intensity contour provides speech with what is commonly known as volume
and rhythm, respectively. It can be derived directly from the energy of the
time-signal of the recording. As with other measures of this kind, this should
be done on an agreed set of utterances.
The manner of speaking and the very ability to speak depends
on the ability to hear. For that reason it is recommended to check for
potential hearing impairment of subjects to be recorded, at least in case of
doubts. Appropriate tests are given by pure-tone audiometry and
so-called speech audiometry (cf. Section 8.3.2). Audiometric
``functionality'' of talkers becomes crucial in recordings in which
acoustic feedback or stimulation is planned during the recording.
Various diseases, such as inflammation of the middle-ear can
significantly degrade hearing properties, even if they occurred decades
earlier. For this reason we recommend asking potential candidates if they happen
to suffer from any such disease, and to ask for the anamnesis.
- Average Noise Consumption:
-
The kind and amount of noise a subject is
frequently exposed to gives a clue to possible hearing losses as well as to
the degree to which he is accustomed to noisy environments.
A person, for example, who is used to professionally communicating in noisy
environments exhibits significantly better listening performance than
inexperienced listeners. The average noise is measured by its level, duration
and spectral characteristics. A comprehensive discussion on the judgement of
effects and figures of everyday noise loads can be found in [Rose (1971)].
- Experience:
- Experience in listening experiments clearly enhances
performance in such tests. For this reason we recommend always establishing a
``listening test record'' for all members of a test population.
Primarily this should include the types of test the subject is experienced in.
A ``normalisation'' of all listeners with respect to experience, however, can
generally be achieved by giving dummy examples prior to the actual experiment.
Pure tone audiometry provides a measure of the hearing sensitivity as a
function of frequency . It is measured by air conduction and by bone
conduction. In addition to the absolute sensitivity in dB-SPL, a pure-tone
audiogram also displays how much a subject deviates from the average listener
and whether this deviation is within an admissible range or not.
The technical setup and procedure is standardised to a high degree (ISO 1964)
and appropriate test equipment is widely available.
For further details on pure-tone audiometry consult [Rose (1971)].
The goal of speech audiometry is to investigate the listener's response to
speech. Despite theoretical and practical difficulties, it provides a
method by which such assessment can be made. It is almost too obvious to state
that it is not normally necessary to attend to or discriminate among pure-tone
stimuli, but rather it is constantly necessary to identify speech
units. Speech audiometry is concerned with answering the three questions:
- What is the lowest intensity level at which a listener can identify simple speech fragments?
- How well does a listener understand everyday speech under everyday conditions?
- What is the highest intensity at which the listener can tolerate speech.
Though not really standardised, certain standard procedures for the speech audiometry have been established during recent decades. For comparison between separately tested populations, however, the exact test configuration and procedure has to be recorded.
For further reading consult [Barry & Fourcin (1990), Kasuya et al. (1993), Michaelis & Strube (1995), Rose (1971)].
Next: Transducer characteristics
Up: Talker / listener descriptors
Previous: General (demographic) descriptors
EAGLES SWLG SoftEdition, May 1997. Get the book...