As mentioned above, this handbook contains a chapter dedicated to speaker verification and speaker identification (Chapter 11) giving details about the technical approaches. A particular section of that chapter is related to the ``levels of text dependence'' with a focus on the text-dependent versus the text-independent approach and a mixed strategy.
The system may use a text dependent approach: the user has to pronounce a specific sentence (or set of words/sentences) expected by the system. The application developer has to know how appropriate they are to his application. If they are not, he has to know how they have been selected. It is convenient that such a set of sentences can be changed from time to time; therefore he has to know how to choose new ones and what kind of training is needed (A new training phase has to be carried out, slight and minor adaptation is recommended, nothing to change!).
The system may use a text independent approach: the system does not know what the user will utter. Typically the system asks questions (personal ones such as How old are you, How many children do you have, etc.). The system uses the uttered answers to identify/verify the speaker and may use the answers (a speech recognition is then activated to recognise what has been said) to double check in a database for consistency. The application developer has to know whether some specific tuning is needed.
There are some hybrid systems which use a pre-defined list of words/sentences from which they choose in an arbitrary way the word/sentence to be spoken by the user. The system can also mix the two approaches starting with a text independent system and ending up with a text dependent one.
For the training process an amount of speech is needed to achieve a given performance. If the data collection is carried out by the application developer he has to know the size of the corpus to be collected.
The technology provider has to indicate the identification/verification performance correlated to the speech input duration which is shown in Figure 2.7.
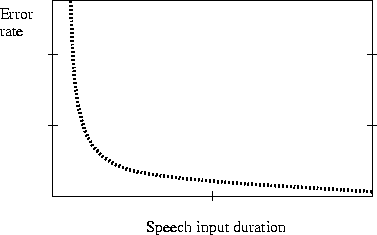
Figure 2.7: Error rate related to speech input duration
The speech duration may be used for a pre-selection of a subset of speakers (using for example a short sentence of less than 2s) and then request another sentence to identify the speaker.
The quality of speech is one of the major influencing factors and mostly depends on the acquisition device and conditions (microphone , telephone, bandwidth , acoustic environment, etc.). Some of these factors have been pointed out in the previous section about ``Speech recognition systems'' and will be elaborated upon in Chapter 10.
The technology provider may need to collect speech data regularly for training purposes because of the variation of speech and speaker characteristics in the course of time. This has to be clearly stated and the application developer should know how to accomplish this task and how frequent it is.
Some systems carry out training based on a discriminant principle that involves a mutual information process. The optimisation is done so as to account for all speakers. In this case, adding a new speaker or removing one from the list of speakers to be identified requires a complete new training session. This may be done by the application developer using a black box procedure or he may use some hints and know-how that should be clearly indicated by the technology developer (e.g. adjustment of thresholds). An intermediate solution may be offered to allow adding or removing speakers without proceeding to a new training. The performance degradation should be clearly estimated.
If the training process does not involve this mutual information then the application developer has to know how to modify his dictionary to add or remove a speaker.