The different errors are summarised in Table 2.3.
The application developer may have access to the different parameters that determine the system performance. These parameters may be directly correlated to given threshold or confidence levels. For example, he may accommodate the thresholds in order to obtain an equal error of false acceptance and false rejection as well as a confidence area as depicted in Figure 2.6. The technology provider should indicate how to handle such parameters. He also should indicate whether such parameters are speaker independent or speaker dependent. If these are speaker-dependent parameters then he should know how to obtain and optimise them.
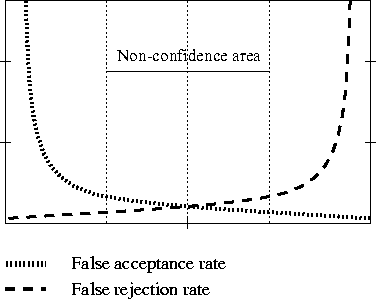
Figure 2.6: False acceptance versus false
rejection
The speaker identification process depends on the size of the population, and the criteria indicated above for the speaker verification process should account for that. The error measures should also consider the confusion that may occur between two different speakers (the substitution possibility of identifying user E instead of the present user U). A particular summary is given in Table 2.4.
Substitution errors are more severe than the others because unauthorised speakers or impostors may thus gain access to confidential data. As the prime motivation for integrating speaker identification procedures is to achieve more reliable personal identification in a convenient manner this has to be used with other techniques.
In practical application one imagines that the users are motivated and hence are very cooperative. Meanwhile the impostors are unknown speakers and there is no way to collect data to prepare a rejection model based on an ``impostor model''.
The application developer has also to know how to calibrate the different thresholds to obtain the best compromise between false acceptance , false rejection and substitution errors.
In some particular applications dealing with speaker verification, a confusion matrix may be requested in order to allow a pre-selection of several candidates in a first phase and then consider a second process with a small subset of speakers.