Estimation is used for making decisions about populations
based on simple random samples . A truly random sample is likely to
be representative of the population; this does not mean that a
variable measured on a second sample taken will be the same as the
first. The skill involved in estimating the value of a variable is
to impose conditions which allow an acceptable degree of error in
the estimate without being so conservative as to be useless in
practice (an extreme case of the latter would be recommending a
sample of the same order of magnitude as the population). The
necessary background skill is to understand how quantities like
sample means, proportions and variances are related to means, proportions
and variances in the population. The following notation is used in the
discussion: ![]() is the sample mean, S is the sample standard deviation,
and S
is the sample mean, S is the sample standard deviation,
and S![]() is the sample variance;
is the sample variance;
![]() is the population mean,
is the population mean, ![]() is the population standard deviation,
and
is the population standard deviation,
and ![]() is the population variance.
The abbreviations sd and S.D. are sometimes used
for standard deviation; S.E. is used for standard error, Z is used for
z-scores, P stands for estimated probability,
and p stands for proportion.
is the population variance.
The abbreviations sd and S.D. are sometimes used
for standard deviation; S.E. is used for standard error, Z is used for
z-scores, P stands for estimated probability,
and p stands for proportion.
A fundamental step towards this goal is to relate the sample statistic to a probability distribution: What this means is: if we repeatedly take samples from a population, how do the variables measured on the sample relate to those of the population? To translate this to an empirical example: How sure can you be about how close your sample mean lies to the population mean? Even more concretely, if we obtain the mean of a set of samples, how does the mean of a particular sample relate to the mean of the population. As has already been said, the value of the mean of the first of two samples is unlikely to be exactly the same as the second. However, if repeated samples are taken, the mean value of all the samples will cluster around the population mean; this is usually regarded as an unbiased estimator of the population mean.
The usual way this is shown is to take a known distribution (i.e., where the population mean is known) and then consider what the distribution would be like when samples of a given size are taken. So, if a population of events has equally likely outcomes and the variable values are 1, 2, 3 and 4, the mean would be 2.5. If all possible combinations are taken (1 and 2, 1 and 3, 1 and 4, 2 and 3, 2 and 4, 3 and 4), the mean of the mean values for all pairs is also 2.5 (taking all pairs is a way of ensuring that the sample is simple random). An additional important finding is that if the distribution of sample means (the sampling distribution) are plotted as a histogram , the distribution is no longer rectangular but has a peak at 2.5 (1 and 4, and 2 and 3 both have a mean of 2.5 and none of the means of the other pairs has the same mean). Moreover the distribution is symmetrical about the mean and approximates more to a normal (Gaussian) distribution even though the original distribution was not. As sample size gets larger the approximation to the normal distribution gets better. Moreover, this tendency applies to all distributions, not just the rectangular distribution considered. The tendency of large samples to approximate the normal distribution is, in fact, a case of the Central Limit Theorem.
This particular result has far-reaching implications when testing between alternative hypotheses (see below). As a rule of thumb sample sizes of 30 or greater are adequate to approximate the normal distribution.
The statistical quantity standard deviation (sd, S.D.) is a measure of how a set of observations scatter about the mean. It is defined numerically as
![]()
Later the related quantity of the variance will be needed. This is simply the sd squared:
![]()
An important aspect of the situation described is that the sample means themselves (rather than the observations) have a standard deviation (sd ). The sd of the sample means (here the sd of all samples of size two for the rectangular distribution) is related to the sd of the samples in the original distribution by the formula:
![]()
This quantity is given a particular name to distinguish it
from the sd - it is called the standard error (S.E.). In practice, the standard deviation of the population is
often not known. In these circumstances, provided the sample is
sufficiently large, the standard deviation of the sample can be
used to approximate that of the population and the above formula
used to calculate the S.E. The S.E.
is used in the computation of another quantity, the z score
of the sample mean:
![]()
The importance of this quantity is that the measure can be translated into a probabilistic statement relating the sample and population means. Put another way, from the z score , the probability of a sample mean being so far from the population mean can be computed.
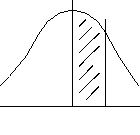
To show how this is used in practice: if a sample of size 200 is taken, what is the probability that the mean is within 1.5 S.E.s of the population mean? Normal distribution tables give the desired area. Here is a section of a table giving the proportion of the area of a normal distribution associated with given values of z (the stippled section in the figure indicates what area is tabulated):
| z | Area |
| |
| . . . | . . . | ||
| 1.3 | 0.4032 | ||
| 1.4 | 0.4192 | ||
| 1.5 | 0.4332 | ||
| 1.6 | 0.4452 | ||
| . . . | . . . |
The sketch of the normal distribution is symmetrical and the symmetry is about the mean value (i.e., the peak of the distribution). The z values above the mean are tabulated, and the row with a z value of 1.5 indicates that 0.4332 of the area on the right half of the distribution lie within 1.5 S.E.s above the mean. Since it has already been noted that the distribution is symmetrical, 0.4332 of the area will lie within 1.5 S.E.s below the mean. Thus, the area within 1.5 S.E.s above or below the mean is 0.4332 + 0.4332, or 0.8664. Thus, converted to percentages, approximately 86.6% of all samples of size 200 will have means within 1.5 S.E.s of the population mean. If, as in any real experiment, one sample is taken, we can assign a statement about how likely that sample is being within the specified distance of the mean.
Another, related, use of S.E.s is in stipulating confidence
intervals. If you look at the areas associated with particular z
values in the way just described, you should be able to ascertain
that the area of a normal distribution enclosed within z values
![]() S.E.s of the mean
S.E.s of the mean ![]() is 95%.
Thus, if the S.E. and mean
is 95%.
Thus, if the S.E. and mean ![]() of a sample are known, you can specify a measurement interval that
indicates the degree of confidence (here 95%) that the population
mean will be within these bounds. This is between the value 1.96
of a sample are known, you can specify a measurement interval that
indicates the degree of confidence (here 95%) that the population
mean will be within these bounds. This is between the value 1.96 ![]() the S.E below the sample mean and 1.96
the S.E below the sample mean and 1.96 ![]() the S.E. above the sample
mean. This particular interval is called the 95% confidence
interval. Other levels of confidence can be adopted by obtaining
the corresponding z values.
the S.E. above the sample
mean. This particular interval is called the 95% confidence
interval. Other levels of confidence can be adopted by obtaining
the corresponding z values.
Since this topic is so important, an example is given: Say a
random sample of mean voice fundamental of 64 male university
students has a mean of 98Hz and a standard deviation of 32Hz.
What is the 95% confidence interval for mean voice fundamental of
the male students at this university? The maximum error of the
estimate is approximated
(using sample standard deviation S
rather than that of the population ![]() as an approximation, see above) as:
as an approximation, see above) as:
![]()
Thus, the 95% confidence interval is from 98 - 7.84 = 90.16 to 98 + 7.84 = 105.84. Often, the confidence intervals are presented graphically along with the means: the mean of the dependent variable is indicated on the y axis with some chosen symbol; a line representing the confidence interval extends from (in this case) 90.16 to 105.84 and it is drawn vertically and passes through the mean.
Before leaving this section, it is necessary to consider what
to do when wanting to make corresponding statements about
small-sized samples which cannot be approximated with the normal
distribution. Here computation of the mean ![]() and standard error
S.E. proceeds as before. Since the quantity z is used in
conjunction
with the normal distribution tables, it cannot be used. Instead the
analogous quantity t is calculated:
and standard error
S.E. proceeds as before. Since the quantity z is used in
conjunction
with the normal distribution tables, it cannot be used. Instead the
analogous quantity t is calculated:
![]()
The distribution of t is dependent on sample size n and so (in essence) the t value has to be referred to different tables for each size of sample. The tables corresponding to the t distribution are usually collapsed into one table and the section of the table used is accessed by a parameter related to the sample size n (the quantity used for accessing the table is n-1 and is called the degrees of freedom). Clearly, since several different distributions are being tabulated, some condensation of the information relative to the z tables is desirable. For this reason, t values corresponding to particular probabilities are given. Consideration of t tables emphasises one of the advantages of the Central Limit Theorem insofar as one table can be used to address a wide variety of issues rather than is the case for t.
Here the problem faced is similar to that with means: A sample
has been taken and the proportion of people meeting some criterion
and those not meeting that criterion are observed. The question is
with what degree of confidence can you assert that the proportions
observed reflect those in the population? Once again the solution
is directly related to that discussed when estimating how close a
sample mean lies to the population mean using z scores .
Essentially the z score for means measures:
![]()
The only difference here is that binomial events are being
considered (meet/not meet the criterion). Since the mean of a
binomial distribution is np
(number tested ![]() population proportion)
and the S.E. is
population proportion)
and the S.E. is ![]() where q = 1-p), the z score
associated with a particular sample based on the estimated probability and
the population proportion is:
where q = 1-p), the z score
associated with a particular sample based on the estimated probability and
the population proportion is:
![]()
Normal distribution tables can again be used to assign a probability associated with this particular outcome.
To illustrate with an example: Suppose that it is expected
that as many men will use the ANN
system as will women
(p (man) = p (woman) 0.5).
What size of sample is needed to be 95% certain that the
proportion
of men and women in the sample differs from that in the population
by at most 4%?
![]()
Solving for n gives 600.25. Therefore, a sample of size at least 601 should be used.
Now what are the effects if we want to be more than 4% confident, say if the difference is reduced to 2%. The required sample size jumps to 2401.
The relationship between the variance of a sample and that of
the population is distributed as ![]() (chi squared)
with n-1 degrees of freedom.
(chi squared)
with n-1 degrees of freedom.
![]()
Thus, if we have a sample of size 10 drawn from a normal population with population variance 12, the probability of its variance exceeding 18 is:

This has associated with it 9 degrees of freedom. Because ![]() values are only tabulated for particular probabilities (as
with t), the probability can only be estimated for limited
probabilities. In this case
values are only tabulated for particular probabilities (as
with t), the probability can only be estimated for limited
probabilities. In this case ![]() lies between 0.2 and 0.1.
lies between 0.2 and 0.1.
If two independent samples are taken from two normal
populations with variance ![]() and
and ![]() , the ratio of
the
two variances (
, the ratio of
the
two variances (![]() and
and ![]() ) has the F distribution:
) has the F distribution:
![]()
If the two samples (which can differ in size) from the same normal population are taken, then the ratio of the variances will be approximately 1. Conversely, if the samples are not from the same normal population, the ratio of their variances will not be 1 (the ratio of the variances is termed the F ratio ). The F tables can be used to assign probabilities that the sample variances were or were not from the same normal distribution. The importance of this in the Analysis of Variance (ANOVA) will be seen later.