It is obvious that for speaking experiments the auditory domain plays by far the most important role of all environmental factors. At this point we assume a studio situation, i.e. a speech recording in an anechoic chamber , and concentrate on how to provide a talker in such a situation with a reasonable impression of the room's characteristics without corrupting the speech signal at the same time. The focus is on simulation of just any room instead of a particular one; the primary goal is to avoid unwanted psychoacoustic effects due to the missing information characteristic of rooms in general.
As basic knowledge one has to understand the main acoustic components that influence the perception of one's own voice. These are:
The dilemma is that for the purpose of providing an acoustic signal to the talker without disturbing the actual speech data we need to equip him with headphones . But what type of headphone is to be chosen and how can we compensate for its effect with regard to self-perception? How to actually simulate a room, once proper headphone compensation has been installed, and how this gives access to all kinds of acoustic subject conditioning will be discussed in Section 8.5.2.
A comprehensive elucidation of various aspects of ``Vocal Communication in Virtual Environments'' can be found in [Lehnert & Giron (1995)].
One could be tempted to say that closed headphones are the ideal solution to the problem of providing a talker with sound. Unfortunately, they are not.
First of all, even hearing protectors which are specially designed to be as ``closed'' as possible do not provide perfect insulation; especially at low frequencies acoustic shielding is poor. This effect is even more pronounced for closed headphones. The difference between open and closed headphones is a qualitative one and not a principled one, and the terms are somewhat misleading.
A closed headphone will change the radiation impedance at the end of the auditory channel towards the free sound field and therefore the in-head sound transmission mechanism of the voice will be severely affected. Equalisation of this effect, especially at higher frequencies, is very difficult to achieve.
Another effect caused by modified radiation impedance is that sensitivity to hearing one's own blood flow is increased. Also, sounds that are at least partly perceived by the body, e.g. one's own footsteps, are greatly modified and in general sensitivity to structure-transmitted sounds is increased.
The only benefit of using closed headphones is that external sound is shielded somewhat better than with open headphones. but in a rather quiet environment, such as an anechoic chamber , this should in any case not be of major concern. In the other direction, i.e. from the headphone to the microphone , it is necessary to be aware of the possibility of undesirable feedback (cf. Section 8.5.2).
It is always recommendable to use open headphones for the sound conditioning of a talker.
Sound reproduction can be performed in two ways, namely by either using loudspeakers or by using headphones. Only headphones offer a means of reproducing sound in a systematic and well-defined manner. However, for that purpose a specific headphone or a specific kind of headphone must be chosen.
The easiest method of equalising a headphone would be to equip it with a flat frequency response. But this would result in a very unnatural sound. The reason for this is that the human outer ear, the head and the torso are a direction-dependent filter for incoming sounds. That means that the spectral shape of a sound event changes depending on its direction. Our brain is able to do inverse filtering with respect to the sound source position. The result is that when a sound source rotates around a listener's head the perceived timbre of the sound remains more or less unchanged, although the spectrum of the sound measured at the ear drum changes dramatically. The consequence of this effect is that a headphone can only be equalised correctly for a particular condition of sound incidence.
Recently, two equalisation techniques have been developed. The first one is the so-called Free-Field Equalisation. A free-field equalised headphone produces the same spectral distribution of sound at the ear drum of the listener as does an ideal loudspeaker placed under free-field conditions (e.g. comparable with an anechoic chamber ) in front of the listener.
The second one is the so-called Diffuse-Field Equalisation. A diffuse-field equalised headphone, when fed with white noise, produces the same spectral distribution of sound at the ear drum of the listener as appears in a diffuse field. In a diffuse sound field the direction of incidence is evenly distributed over all directions (e.g. in a reverberation chamber).
Most of the sound signals that are to be reproduced via headphones consist of incoming sounds from various directions. Such sound signals would require the use of a diffuse-field equalised headphone, because this type is the better choice in the sense of ``least mean error''. Even for sound sources coming from a single direction the diffuse-field equalised headphone is the better choice when the direction of incidence is not close to the forward direction.
Another point is that the free-field equalisation function varies from person to person much more than the diffuse-field equalisation function does. So an averaged diffuse-field equalisation function is valid for more people.
Both the diffuse-field equalisation function and the free-field equalisation function have been standardised, but so far, there are still differences among diffuse-field equalised and free-field equalised headphones made by different manufacturers.
The most important reason for choosing diffuse-field equalised headphones is that recordings made for diffuse-field equalised headphones also yield good results when reproduced via loudspeakers and vice versa. Using diffuse-field equalised headphones offers the best compatibility to common recording techniques, at least in the opinion of many experts.
When making recordings using binaural simulation techniques, the catalogue of outer-ear transfer functions should also be diffuse-field equalised.
The Stax is an electrostatic headphone and it is delivered together with a preamplifier which contains the diffuse-field equalisation. It is probably the best headphone available on the market, but it is very expensive. All headphones are open except of Sennheiser's HD 250 which is a closed type. The company ``Beyer'' sells a headphone which is delivered together with a passive network for diffuse-field equalisation.
In the SAM Project, the AKG 240 DF was selected as a low-cost standard headphone, while the Stax SR with diffuse-field equaliser is a good choice as a highest-quality reference system .
Since the subject wears a headphone, the transmission of the speech sound through the air around the head is significantly disturbed. In order to model natural self-perception of the voice, this effect has to be compensated for.
The sound field outside the head can be considered as a linear area that is free of sound sources. In such an area the sound pressure signal at any point can be reconstructed from the sound pressure signal at any other point just by knowing the correct transfer function between both points. The task of measuring this transfer function is similar to the well-known procedure of determining a Head Transfer Function: miniature microphones are placed at the entrance of the blocked auditory channels. While speaking, the sound pressure signals at the reference point (recording microphone ) and the ear microphone are recorded simultaneously. The magnitude of the transfer function may be obtained by averaging the energy of the short term spectra of both signals and dividing the resulting values at the ear drum by those measured at the reference point. During this procedure the phase information is lost. A plausible phase can be generated by calculating the minimum phase function. The same procedure has to be done with the subject wearing the headphone such that the resulting compensation function is given to 1-l(f), where l(f) is the result of complex valued division of both transfer functions.
A sensitive matter is the choice of the reference point; if authentic compensation is desired, this point, i.e. the recording microphone , must be located as close to the mouth as possible and it must not move significantly during a recording session. The use of high-quality headsets is therefore strongly recommended for that purpose.
Since the level of compensation is critical, the insertion-loss compensation function has to be determined for each talker individually.
A rather practical approach to the problem of insertion-loss compensation is to ask the subject to just turn the gain of his own speech signal - equalised with the Head Transfer Functions of the ear-to-mouth direction and fed back to the headphone - up to the point where it sounds as ``normal'' as possible.
Feedback compensation, i.e. the compensation for possible sound transmission from the headphones to the recording microphone , is not considered to be necessary.
If pure headphone compensation and room simulation is requested, sound is only emitted from the headphones simultaneously with the speech and thus would not degrade the signal-to-noise ratio of the recorded signal.
Commonly used background sound, such as concurrent speakers or an underlying noise floor that might be intended for subject conditioning should also not jeopardise the speech quality . A sensitive upper limit for those conditioning signals is considered to be a sound pressure level of 85db.
Above this limit, audible feedback from the headphone to the recording microphone should be taken into account during non-speaking intervals.
Spatial auralisation of sources can be performed by real-time filtering of sound signals with the Head Transfer Function of the talker in combination with a modelling system that calculates the spatial map of secondary sources and the corresponding filter functions. In a successive stage the contributions of all secondary sources are filtered with the Head Transfer Functions for the corresponding directions of incidence. Figure 8.8 displays the auditory subsystem of the so-called SCAT-LAB that has been developed in the course of the ESPRIT basic research project 6358 SCATIS (Spatially Coordinated Auditory/Tactile Interactive Scenario). Since SCATIS was originally designed for unidirectional simulation (passive subject) it has been augmented according to the needs for speech recordings in anechoic chambers , i.e. microphone feedback to the DSP-network has been established, and the database has been expanded by the insertion-loss compensation function of the headphone.
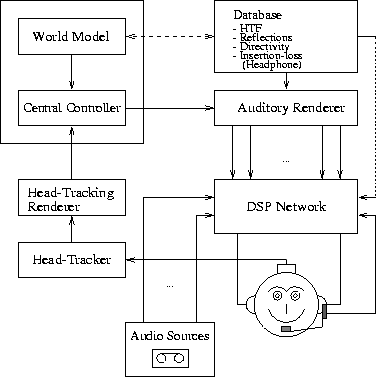
Figure 8.8: Augmented auditory subsystem of the SCATIS VE generator
With respect to the modelling of room acoustics, the subject's voice is a sound source like any other and may be modelled as such, though with a few exceptions:
Up to this point we have described how to properly compensate for disturbing acoustic effects due to insufficient self-perception resulting from the headphone, or due to missing sound reflections in an anechoic chamber . In fact the technical setup for this also allows for a virtually unlimited range of acoustic conditioning of the subject. This includes ordinary noise of defined level and spectra, or simple monaural interaction between the talker and the recording manager, as well as complex scenarios such as dialogues in the entrance hall of a railway station with incoming trains, heavy reverberations , and concurrent speakers from different directions. Additional sounds such as these may come from a tape or they may be played in on-line. In Figure 8.8 this is summarised in the block labelled ``Audio Sources''. For later mixing and scenario analysis it is advisable to synchronise the recorded speech with the background signal.
The following recommendations are given for speech recordings in a very quiet recording environment (e.g. an anechoic chamber ) that deprives the talking subject of most of its ``natural'' room impression. The goal is to compensate for this deficit and to decouple any acoustic feedback to the talker from the actual speech recording at the same time: