Due to the different possibilities of producing, processing and exploiting spoken utterances there exists a tremendous variety in the architecture of the so-called communication chain. Therefore we define the communication chain as the connection(s) between a talker and a listener via an auditory, a visual and/or an electric channel . While these are parallel channels of information flow, the electric channel as well might be seen as serial and/or parallel connections of electric devices and channels. Figure 8.1 may give a rough impression of this somewhat simplified scheme.
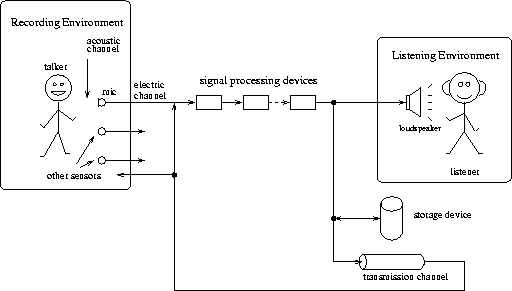
Figure 8.1: Scheme of the communication chain
This scheme consists of the following elements:
In this chapter we differentiate between two opposite strategies for the actual specification of a communication chain. The first strategy, called the ideal or flawless approach , tries to capture the speech signal as cleanly as possible in a domain and scenario independent way. The advantage is that these data may be applied to many tasks with ``average'' suitability, without being ideally adapted to their specific conditions. Another advantage is given by flexibility in exploiting the same data: many post-processing possibilities exist so that many task-specific signal characteristics may be imposed after the recording itself. But the talker's conditions and some environmental factors are also reflected by the ``clean'' data, and the possibilities of subsequent corrections or manipulations are limited. To yield so-called flawless speech, we have to consider the dilemma of motivating a natural way of speaking on the one hand and optimising the more technical circumstances of the recording session on the other hand. One has to come to a minimum set of decisions: what kind of speaker (cf. Section 8.3), what kind of auditory and visual environment (cf. Section 8.5) and how to capture the speech signal in an optimal way (cf. Section 8.4).
The opposite recording strategy may be called a real-life or on-site approach: From the beginning the communication chain is adapted to a specific scenario as closely as possible. For instance, if a speech recognition device that makes up a part of an information system for in-car inquiries via a mobile phone is to be evaluated, the speaker has to sit in a moving car, he has to drive the car himself and the speech data have to be transmitted over the wireless telephone network. As in similar cases, the simulation of the acoustic environment is not the crucial point, but the situation-dependent speaking style influences the resulting speech signal significantly. Within this approach we find the dilemma of ensuring real-life conditions on the one hand while performing the recording in an optimal way on the other hand.