All types of speech, whether read or spontaneous , whether monologue or dialogue, can be represented at different levels and in different ways. A distinction may be made between transcriptions and representations that can be derived from transcriptions. In making a transcription, it is necessary to monitor the actual speech. This can be done by the human ear or by means of a computer program. In the case of representations derived from transcriptions, it is not necessary to refer to the actual speech. These representations can be made at the phonemic level, and also at the morphological, syntactic , semantic, and pragmatic levels.
An orthographic transcription is often referred to as a ``transcript'' in courts of law (e.g. a transcript from a tape).
A distinction is made between the following types of annotation, which will be discussed in detail in the following sections. It is possible for all these levels of annotation to be time-aligned with the speech signal. However, time alignment is most likely to be used in the case of the prosodic , physical, acoustic-phonetic, narrow phonetic and (possibly) broad phonemic levels.
Figure 5.1 exemplifies the different levels, based on material in [Barry & Fourcin (1992)].
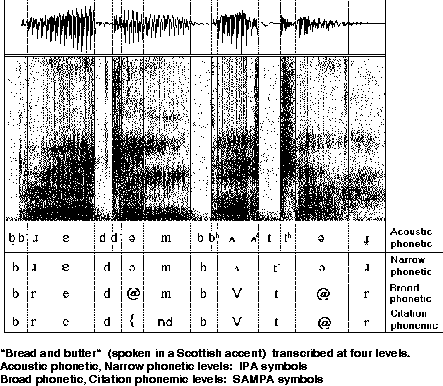
Figure 5.1: Levels of annotation