The scope of the handbook fundamentally addresses the resources required for specifying, developing and evaluating spoken language technology components, including automatic speech recognition , speaker recognition and speech synthesis, which themselves are integrated to form interactive systems such as spoken dialogue systems. There is an emphasis upon the design, collection, representation, characterisation, storage and distribution of speech corpora, as well as upon assessment methodologies for the component technologies and integrated systems.
The handbook is essentially divided into four main parts. The first part (Chapters 2 to 5) is concerned with the design of spoken language systems and addresses spoken language resources (the design, collection, characterisation and annotation of corpora). The second part (Chapters 6 to 8) is concerned with spoken language characterisation (spoken language lexicon design, language models, and physical characterisation). The third part (Chapters 9 to 13) covers assessment methods (for recognition, synthesis, verification and interactive systems) . The fourth part is a substantial body of reference material.
One of the difficulties which arises from the complexity of the human-computer interface (HCI) and the position of spoken language within it, is that people concerned with implementing applications are unable to select appropriate HCI components (such as automatic speech recognisers , for example). This arises not just from a lack of standardised evaluation criteria for system components but also from a lack of clear understanding of the implications on overall performance of the performance of each system component.
One possible model for understanding the relationship between spoken language system applications and the corresponding technology is illustrated in Figure 1.5. The key notion which sets it apart from previous models developed by the spoken language R&D community is that it not only focuses on the fact that there are many factors which influence the performance of spoken language systems and that it is necessary to distinguish between ``capabilities'' and ``requirements'', but it also emphasises that the purpose of introducing spoken language technology into an application is to achieve the appropriate operational benefits. It is only when all of these features become properly integrated into agreed methods for spoken language system assessment that it will be possible to arrive at a meaningful (and comprehensive) definition of the ``suitability'' of particular technologies for particular applications.
The model shown in Figure 1.5 indicates clearly that successful implementation of spoken language systems depends only indirectly on the technical features of the system components and on the operational benefits being sought in the applications themselves. What is more important is to develop a process for converting technical features into technical and operational capabilities , and for converting operational benefits into operational and technical requirements. These processes were felt by the Working Group to be so important to the system design process (and hence to the success of the technology in the market place), that a chapter outlining design issues should take pole position at the front of the handbook (Chapter 2).
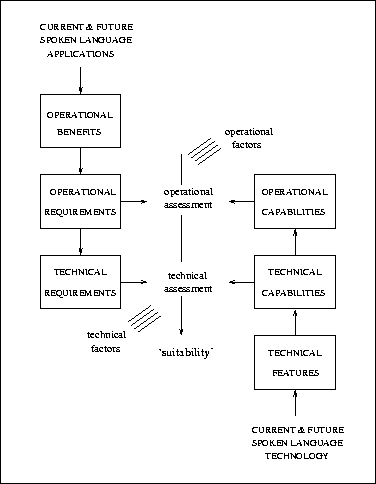
Figure 1.5: A model of the relationship between the applications of spoken language systems and the underlying technology
Broadly speaking, the spoken language R&D community can be partitioned into two main interest groups: those concerned with ``speech science'' and those concerned with ``spoken language technology''. In the main, speech science is the domain of phonetics , linguistics and psychology, and spoken language technology is the domain of engineering, computer science, mathematics and AI. Both areas have a strong need for significant quantities of both transcribed speech data (orthographic, phonetic, prosodic etc.) and digitised acoustic speech recordings (together with the means for accessing selected subsets of the material using the relevant transcriptions and annotation ).
Three types of recorded speech are typically of interest [Moore (1992b)]:
Clearly general purpose speech corpora are easy to collect and are useful in a general sense but, of course, they have only limited practical value. On the other hand, although task-specific corpora can be time-consuming to collect and are only relevant to a specific domain, they are obviously directly useful for the purposes of commercial exploitation. Diagnostic corpora are time consuming to design, but they are extremely useful for research purposes and, in the long term, could prove to be the most valuable resource for spoken language R&D.
At the current time there is a growing requirement for recorded speech which is in some sense more ``natural'' than the so-called ``lab-speech'' that has been normally collected and studied up to now. This is true for all three types of material identified above. In this context a range of different speaking styles are now of interest: read speech - including talkers with different amounts of formal training and familiarity with the subject matter, spontaneous speech arising from a directed monologue , spontaneous speech arising from a dialogue between human interlocutors, spontaneous speech arising from simulated human-computer interaction - using the so-called ``Wizard of Oz'' protocol, and spontaneous speech arising from ``real'' human-computer interaction .
These issues (and the technology required for acquiring spoken language data ) are presented in depth in the handbook chapters on spoken language corpus design (Chapter 3) and collection (Chapter 4).
Of course, recorded spoken language data is, in itself, of limited value; the raw acoustic signal needs to be associated with the appropriate phonetic and linguistic transcripts. This is achieved by ``annotating'' the data with markers which make such relationships explicit and which provides the means by which the data can be accessed, thereby facilitating the organised study of the data and both automatic parameter estimation and assessment for spoken language systems. These issues are dealt with in the chapter on spoken language corpus representation (Chapter 5).
An important linguistic component of any spoken language corpus , and a key feature of a spoken language system, is the set of words that are employed and their associated properties (such as information about pronunciation, grammatical and semantic features) - the ``lexicon''. This area is treated in the chapter on spoken language lexica (Chapter 6).
Another key linguistic aspect of spoken language which has particular relevance in spoken language technology systems, is concerned with ``language modelling'' (Chapter 7).
As well as the linguistic characterisation of spoken language corpora described above, there is also a need to be able to characterise such data from an acoustical and electrical perspective. All aspects of the recording chain become important, from the nature of the recording environment , through the types of microphones or headphones that might be used, to issues such as methods for calculating the signal-to-noise ratio . These factors are presented in the chapter on the physical characterisation of spoken language corpora (Chapter 8).
In the assessment of spoken language systems it is possible to distinguish three main methodologies: live ``field'' trials , laboratory-based tests and system modelling paradigms [Moore (1992a)]. The first of these of course is likely to provide the most representative results but, from a scientific point of view, there are likely to be a number of uncontrolled conditions and this limits the degree of generalisation that can be made from application to application. Field trials also tend to be rather costly operations to mount. Laboratory testing is per force more controlled and can be relatively inexpensive, but the main problem is that such tests may be unrepresentative of some (possibly unknown) key field conditions and give rise to the observed large difference between performance in the laboratory and performance in the field . The third possibility, which is itself still the subject of research, is to model the system (and its components) parametrically. In principle, this approach could provide for a controlled, representative and inexpensive methodology for assessment but, as yet, this area is not sufficiently well developed to be useful.
Also, the term ``assessment'' covers a range of different activities. For example, a suitable taxonomy of assessment activities should include:
Given the complexity of the human-computer interface discussed above, it is clear that assessment protocols are required which address a large number of different types of spoken language system. For example, such systems range from laboratory prototypes to commercial off-the-shelf products, from on-line to off-line systems, from stand-alone to embedded systems, from subsystems to whole systems and from spoken language systems to spoken language based HCI systems.
The majority of research in the area of spoken language system assessment has concentrated on evaluating system components (such as measuring the word recognition accuracy for an automatic speech recogniser , for example) rather than overall (operational) effectiveness measures of complete HCI systems. Since the publication of the NBS guidelines in 1985, there have been considerable developments at the international level. In Europe, the ESPRIT SAM project established a standard test harness for both recognisers and synthesisers and in the US a very efficient assessment paradigm has been funded by the Advanced Projects Research Agency (ARPA) which included an efficient production line of ``hub and spoke''-style experiments involving the coordinated design, production and verification of data, distribution through the LDC, and with NIST responsible for the design and administration of tests and the collation and analysis of the results.
These activities point strongly to the importance of establishing appropriate ``benchmarks'' , either through the implementation of standard tests, or by reference to human performance or to reference algorithms.
Throughout these issues, it is vitally important that the relevant practitioners are fully competent in the process of experimental design and in the understanding of key issues such as statistical significance. For these reasons, the handbook specifically includes a chapter on this (Chapter 9) at the front of the chapters on assessment.
The chapter on experimental design is followed by chapters which cover the assessment of the three main component technologies: automatic speech recognition (Chapter 10), speaker verification (Chapter 11) and speech synthesis (Chapter 12). These are followed by a chapter concerned with the assessment of interactive spoken language systems (Chapter 13).
The handbook is structured such that the supporting material for each chapter has been separated from the main text and collated to form a substantial body of reference material spanning all aspects of spoken language standards and resources. The main reference materials covered are: