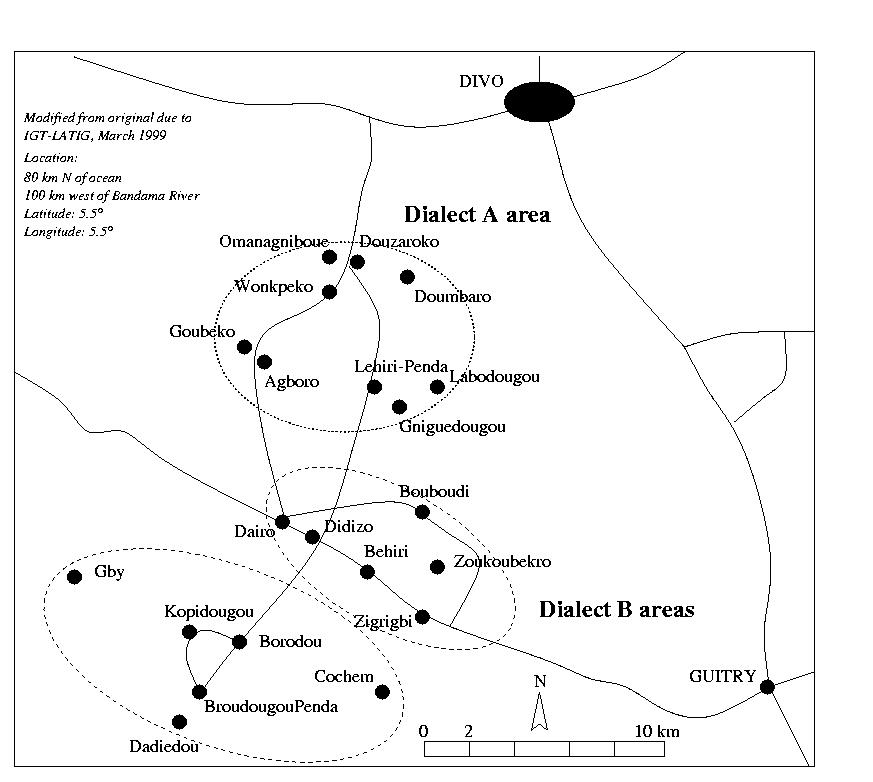
Map of northern (A) and southern (B) Ega village groups
Volkswagen Foundation Programme
Documentation of Endangered Languages
Project proposal (initial phase, 1 December 1999)
EGA: Documentation model for an endangered Ivorian language
Volkswagen Foundation
Kastanienallee 35 / Postfach 81 05 09
D-30519 Hannover
Hannover
z.Hd. Frau Dr. Vera Szöllösi-Brennig
|
Prof. Dr. Dafydd Gibbon
Fakultät für Linguistik und Literaturwissenschaft Universität Bielefeld Postfach 100131 33501 Bielefeld |
Email:
Phone: Secr.: Fax: Mobile: WWW: |
gibbon@spectrum.uni-bielefeld.de
+49 521 106 3510 +49 521 106 3509 +49 521 106 6008/8071 +49 171 680 6327 |
The pilot project aims to develop model documentation for the endangered language Ega, the westernmost Kwa language, a linguistic isolate located in a Kru enclave, with a few hundred remaining speakers, and an unusual linguistic complexity which promises new insight into the history of the Niger-Congo languages. The documentation will develop resource types developed by the proposers in language documentation and technology projects, and existing Ega resources (transcriptions, digital audio/video recordings, a U Cocody, Abidjan, MA thesis). In cooperation with the multimedia database project, a standardised model interactive questionnaire and other survey oriented structured document types, e.g. hyperlexicon and hypertext concordance, will be specified to implementation standard in close cooperation with linguists of the Université de Cocody, Abidjan, and a network of international specialists.
The project is conceived as a model documentation pilot project in the initial phase of the funding programme, with a subsequent two year main phase. The focus is on an endangered Kwa language isolate (called Ega by scientists and Dies by speakers) surrounded by Kru (Dida) in the Ivory Coast, West Africa; a sequel in the form of a main phase project would plan to investigate two other endangered Kwa languages (Betibe and Essouma). The selection criteria for Ega are the number of speakers (estimates range between under 300 according to Ethnologue to somewhat more, based on our own fieldwork contacts), scientific interest (unusual complexity and highly conservative features promising new insights into the history of the Niger-Congo languages), availability of contacts, high speaker motivation and good accessibility.
Ega is the most western of the Kwa languages, the only Kwa language west of the Bandama, River, and an isolate in the Nyo cluster. Interest in high quality documentation of the language is high both on the side of the present proposers and at the Université de Cocody, Abidjan (Département de Linguistique and Institut de Linguistique Appliquée), Côte d'Ivoire, because of its linguistic richness, marked traces of historically old features, the rapid decline in number of speakers due to the high average age of speakers and intermingling with the enclaving Dida (Kru) speaking population.
A good working relationship has already been established with the remaining speakers, and the motivation level of the speakers is high. Although fragmentary documentation of individual features is available, it does not yet have significant documentary value in its present form, and the proposed project is designed to process existing documentation and extend it into a structured data collection based on selected text sorts, a typologically oriented questionnaire, high quality audio and video data, and structured multi-tier annotation procedures.
The resulting documentation is intended to be used by the speakers themselves, the scientific community, and the the Ivorian language planning authorities. In order to ensure adequate international networking, the proposal has been prepared in cooperation with Dr Bruce Connell, U Oxford, and Dr Firmin Ahoua, U Cocody, Abidjan. The members of the proposal group are all experienced field linguists in addition to having competence in computational signal and document processing. The basis for developing sufficiently broad but exact criteria for data selection, collation and analysis will be provided in collaboration with expert field linguists from the Département de Linguistique, U Cocody, Abidjan, and and experienced colleagues from other universities, including Steven Bird and Mark Liberman (LDC; U Pennsylvania), William Leben (U Stanford), Nicholas Ostler (Society for Endangered Languages). Preliminary talks with potential project partners in Germany have also been initiated.
The methodology to be followed has three main dimensions:
Primary data selection, collection and secondary data analysis:
a. selection phase: state of the art typological questionnaire and text sort selection, with scenarios for high quality digital audio and video data;
b. collection phase: systematisation of existing documentation fragments and systematic extension in the field to include representative missing text sorts, and recording of representative digital audio and laryngograph data and, where relevant, video data;
c. description phase: transcription of audio data, initial lexicon construction and morphological analysis, basic syntax analysis, annotation of selected signal files.
Technology: state of the art technological support for standard corpus design, collection, and description methodology based on the Handbook of Standards and Resources for Spoken Language Systems (Gibbon, Moore & Winski 1997), in collaboration with the multimedia database and software development project, with the following phases:
a. definition of procedures and file interchange formats for text, audio, video;
b. joint specification of recording techniques;
c. joint specification of database structure and views;
d. joint specification of intermediate outputs from the documentation project: typological questionnaire in interactive hypertext form, text concordance, LDC-type hyperlexicon and converter tools for database input;
e. joint specification of database outputs in the form of XML DTDs and DSSSL transformations.
Careful coordination of differing needs of speakers, local language planning authorities, and the language documentation community. The ideal local cooperation partner for the project is the Département de Linguistique, in conjunction with the Institut de Linguistique Appliquée, Université de Cocody, Abidjan, with whom long term cooperation is already established and has resulted in numerous exchanges (including a Humboldt fellowship and DAAD scholarships).
The project will cooperate closely with sister projects and in particular with the planned multimodal database and software development project. It will contribute added value by using existing facilities at U Bielefeld developed in related projects on speech technology, in applications of text technology in linguistic documentation, and in large scale computational lexicology of spoken language.
The Département de Linguistique, U Cocody, Abidjan, with whom an official inter-university cooperation exists, is committed to ensuring the availability of fieldword permission and facilities, and will commit a part of the research time of an experienced colleague, and of graduate students with a high level of fieldwork skills, in order to ensure efficient use of resources.
The documentation will be the topic of a doctoral thesis at U Bielefeld, where infrastructural resources (data preprocessing, training, collation tools, equipment) are available.
The leading research scientist designated for the proposed project is an internationally well known expert in West African languages in general, and has worked extensively on endangered West African languages.
In the proposed project, we plan to describe Ega, an endangered and fragmentarily documented language which has been assigned to the Kwa family as the sole member of the Nyo cluster, with the intention to submit a follow-up main phase project on two further endangered Kwa languages. We have selected the Kwa group because of the existence of a wide variety of fairly distantly related languages, the analysis and comparison of which promise on the one hand to further insight into the history of the Niger-Congo languages, and on the other hand are directly relevant to international language planning issues in West Africa.
Ega is the westernmost Kwa-related language, an isolate within the Dida (Kru) speaking area, with no known related dialects. Ega has more complex phonetics, phonology and morphology than other Kwa languages, indicating the presence of reflexes of archaic stages of Kwa language development.
Several social and political factors contribute to the endangerment of Ega. The most salient factors which make Ega a prime candidate as the focal point of a model documentation project, are the following:
Small number of speakers; estimates vary wildly from several thousand two decades ago (Bolé-Richard 1982) to currently less than 300 (Ethnologue); preliminary field investigations indicate that there is a small group of non-proximate Ega villages, with a total but rapidly decreasing population of up to 1000.
Enclaved in the Dida (Kru) speech community.
Speakers perfectly fluent in Dida, which they use as a public language.
Perception of enclaving Dida community as stronger, dominant, efficient, high prestige.
Submissive behaviour with respect to the enclaving Dida community.
Traditional ethnic history relates to the westward Kwa migrations through other Kwa areas (e.g. Abbey) as well as Kru areas, and emphasises status of the Ega community as guests in foreign territories.
Supposition of a centuries old "tukpe" (non-aggression, tolerance) pact with Dida community.
Use of Ega deprecated among Ega speakers; self-characterisation as Dida speakers to outsiders.
Preference for exogenous marriage among Ega men, invariably with Dida women.
Use of French in education official communications and recent introduction of major Ivorian languages to schools e.g. Baule (Kwa), Bété (Kru), effectively requiring Ega speakers to be trilingual or quadrilingual.
The following map shows the area in which the Ega people live. Some of the villages are populated by other ethnic groups (Dida, Avikam, migrant Gur), and the Ega population is scattered through these villages. The area is therefore only sparsely populated with Ega speakers. A distinction between two dialects, indicated as Dialect A and Dialect B on the map, is recognised by Dialect A speakers, though apparently Dialect B speakers do not recognise the distinction. The initial contact village is Douzaroko (official name; called Nyama by Ega speakers).
Map
of northern (A) and southern (B) Ega village groups
From a linguistic point of view, Ega is an appropriate candidate for a documentation project because of its lingusitic richness. Researchers like John Stewart, Bolé-Richard and Clements have raised the question of whether any language may have the complete series of implosives, for example, and preliminary investigations indicate that Ega may indeed be such a case. Ega also exemplifies high complexity in its morphological system. A question of specific interest pertains to the process of language loss by assimilation in its own right, and careful attention will be paid to possible interference and transfer processes in consultating with experts on the enclaving language.
In preparation for the present proposal, Connell and Ahoua have collected laryngograph and digital audio data from six adult male speakers from the village of Nyama-Dies (officially known as Douzaroko, dialect area A on the map), near Divo in inland Ivory Coast. One of the six appeared to speak a dialect of a different village (dialect area B on the map), though he claimed to be an indigene of Nyama; the Nyama indigenes were quick to point out the differences between their speech and his. In addition, a short video film was prepared.
In considering the selection of the most approproate language, we considered a number of questions. Some we were able to answer immediately, others require further exploration and are intended to be addressed in the project. Some of the further questions are:
What percentage of the ethnic group does the number of extant speakers represent?
To how many children is the language still being passed on?
How many of the roles and functions of the language have been passed on to / from the enclaving language?
What is the attitude of the speakers towards their own language? Is this functionally specific or very general?
Is the language related, however distantly, to a non-endangered language which has been well described?
How much information is available on the language?
Given deprecated language usage, are there methods which are appropriate for eliciting documentation material?
The language we have selected scores highly on all of these, especially (1)-(5). As for (1) most Ega people still speak it, and Ega is apparently still being passed on to the current generation of children. But all Ega speakers speak Dida (Kru) perfectly and are rapidly assimilating to Dida. The number of villages shown on the map (see below) with name components of Gur (dougou) and Avikam origin (penda) indicates that the enclaving situation is further complicated by more recent migrant worker settlements (currently a source of political tension in the area).
As already noted, we have verified that field work can be carried out, provided the chiefs and the notables of the respective villages have been contacted beforehand, that one has an official paper from the Institut de Linguistique Appliquée or the Département de Linguistique at U Cocody, Abidjan, clarifying the non-political, and scientific purposes of the investigation.
Preliminary investigations indicated that Ega has the following known linguistic properties which in themselves justify careful and systematic documentation before the language becomes extinct:
The most complete and still active series of contrastive voiced implosive consonants, including palatal, labio-velar implosives in contrast with non-implosives. Mbatto (Kwa) has similar features, but is in the process of losing the contrast.
The most complete nine vowel ATR harmony that consistently operates in prosodic words.
Complex vowel hiatus, described in a recent MA thesis supervised by Firmin Ahoua, one of the project initiators (Dago 1999).
The most complete nominal and gender class prefixes (reported by Bolé-Richard 1983), which have already been widely attested in Bantu, Togo-remnant and Benue-Congo languages, suggesting that the nominal classes have been almost been entirely lost in current Western Kwa, apart from residues in Tano languages such as Nzema-Agni-Baule, and Adiukru. The Potou languages have nominal class prefixes to a larger degree than other languages, but far less than Ega. Ega thus appears to be by far the most conservative of Western Kwa languages, leading to the hypothesis that documentation of Ega will potentially make a significant contribution to the understanding of the unity of the Niger-Congo language family.
A complex conjugation with an intricate tense/aspect system rarely documented among kwa languages (Bolé-Richard 1982).
The proposed project for model documentation of Ega follows the general goals outlined in the Call for Proposals in the following ways:
data orientation: multi-tier annotations of signal data for a range of speech varieties (discourse types) will be provided, accompanied with basic phonetic, phonemic, morphological and syntactic descriptions;
multifunctionality: we propose to cooperate with the database and software development group in providing specifications for efficient data collation and description tools (e.g. standardised labelling software, XML-DTD driven structure editor);
general accessibility: we propose to adopt the consortium oriented technique of using an internet site with telecooperation facilities developed for European language engineering projects (already in place).
Our interest in and contribution to the development and testing of new methods of researching, processing, archiving linguistic and cultural data has developed over many years in close cooperation with West African universities, and in the application of methodologies of computational linguistics and tincludes the application of computational techniques to the documentation of African language data in cooperation with colleagues from Université de Cocody, Abidjan, Côte d'Ivoire. Interdisciplinary orientation has been a feature of linguistic work in the Bielefeld linguistics groups from the beginning, ranging from speech signal data collection and analysis using experimental phonetic and speech technology methods, to the utilisation of this data in internet-based language teaching and in speech recognition and synthesis systems.
As a pilot project, the proposed approach is necessarily experimental and explorative, but we suggest, on the basis of past experience with these methods that they will be successful within a consortium-like management structure. We feel that in such a framework efficient, effective, comprehensive and transferable (exportable) documentation strategies can be developed, and that not only can minimum requirements for documenting an endangered language be defined but also a scale of granularity for creating as detailed a documentation as possible.
The materials which are available to date are somewhat fragmentary, and consist of isolated (and unreliable) comments in more general works, and the following specific material:
Ahoua, F. and B. Connell (1999) 120 minutes laryngograph and speech signal recordings of a set of implosives in Ega with 4 native speakers.
Ahoua, F. and B. Connell (1999): 10 minutes video-film on a Sony Camcorder recording the larynx movement using a mirror.
Bolé-Richard, Rémy. 1982. L'Ega. In Atlas des langues Kwa Vol. 1 ed. By Georges Hérault. ILA: Abidjan.
Bolé-Richard, Rémy. 1983. La Classification Nominale en Ega. Journal of West African Languages XIII, 1.
Bolé-Richard, Rémy. 1983. A word list of Ega. unp. manuscript.
Bolé-Richard, Rémy. 1982. Ega 350 word list in Atlas des langues Kwa vol2. ed. by Georges Hérault. ILA: Abidjan [Vol. 2 of the atlas contains a 350 word list of all the Kwa languages described in vol. 1]
Dago, Georgette. 1999. The Phonology of Ega. Mémoire de Maîtrise, Abidjan [supervised by Firmin Ahoua, contains an extension of Bolé-Richard (1983b.) word list totalling approximately 1000 words.]
These materials will be systematically processed according to the methods outlined in the pilot project work programme. Additionally, with the cooperation of our consultants and other colleagues at U Cocody, Abidjan, further fieldwork will be conducted in order to collect additional primary data types as specified, secondary data types (2000 word lexicon, phonology, morphology, syntax), and basic ethnographic and sociolinguistic information. Initially, in order to avoid slack time, existing tools will be used, and experience with these will be used for acquisition and as operational prototypes for functional requirements specification in discussions with the database and software development group. The existing tools which are currently in use include the following:
hypertext document generation and format conversion tools based on state of the art text technological techniques;
web based database input, maintenance and access (e.g. for archives, project administration, lexical database) to a public domain SQL server (mSQL);
web based structured input to Bielefeld-Abidjan linguistic questionnaire;
hyperlexicon generation tool;
hypertext concordance generation tool.
In addition, we propose to use the following transcription, labelling and phonetic analysis tools:
the Praat freeware phonetic productivity tool (Paul Boersma, U Amsterdam), since this is available for all PC (Windows, Linux), Mac and UNIX workstation platforms;
the Transcriber (LDC, U Pennsylvania; ICP Grenoble) transcription and SGML/XML labelling tool;
the Scicon Acquirer and Pitchworks packages, which are custom designed for fieldwork data acquisition;
standard inexpensive acoustic editing packages such as CoolEdit, SoundForge.
Several social and political factors contribute to the endangerment of Ega. The most salient factors which make Ega a prime candidate as the focal point of a model documentation project have been detailed in the description of the language: the small number of speakers (less than 1000, possibly much less), westernmost Kwa language, an isolate with no known related dialects, enclaved in the Kru area, social and political dominance of Dida speakers (Kru) and use of Dida and French as public languages, deprecation of the use of Ega by the speakers themselves, and exogenous marriage with Dida speaking women, are all powerful factors which mean that the language is likely to disappear in at most two generations.
The situation makes it hard to create reliable census and fieldwork conditions. In fact, in previus attempts to describe Ega fieldworkers have on occasion failed to find Ega speakers, presumably because of unsuitable contact strategies. Because of the deprecated status of the language, it is essential to use appropriate strategies, for instance via female Dida/Ega speakers; the latter strategy was used in establishing contacts in preparation for the present proposal.
The documentation will concentrate on designing and collecting corpora containing different primary data types. The initial classification is as follows (a selection of the following categories used in previous fieldwork and documented in the Bielefeld-Abidjan project questionnaire):
Structured data:
|
Questionnaire-based interview data - unmonitored recording during interview
Elicited discourse data - selection from:
|
In order to minimise the technical effort in collating data, we advise that the database and software development group develop a user-friendly (i.e. GUI oriented) structure editor for use in the project, with a requirements specification which includes the following (see also Work Programme specifications):
XML (eXtended Markup Language) based, driven by XML document type definitions (DTD);
DTD driven entry and entry validation;
import of other markup types (cf. EAGLES Handbook), including word processor document outline styles, single and multi-file HTML documents);
import of (links to) other document objects, e.g. txt, ps, pdf, xls, graphics, video and audio files;
export of XML markup according to individually made custom DTDs;
provision of standard DTDs, for instance of the following document types:
|
Compatibility with the widely used Transcriber project software (LDC, ICP Grenoble).
The emphasis is on the effective systematic collation of data, with a view to multifunctional later use in scientific work and practical applications, and on effective analysis and presentation of secondary data types envisaged in the Call for Proposals, viz.:
an outline of the phonetic system;
a practical orthography;
a linguistic depiction of the language data which has been collected at the morphological/syntactic level represented in a morpheme-interlinear transcription;
a free translation of the documented and transcribed texts;
descriptive and explanatory remarks on every kind of text and language situation; specially collected lexical data;
a collection of morphological forms (e.g. inflexion paradigms);
informant questionnaires for the purpose of clarifying particular aspects.
The audio and video data will be collected digitally, thereby avoiding the post-recording digitalisation stop; format conversions will be performed for data interchange using formats jointly specified by the database and software development group and the documentation projects.
The main activity envisaged for the proposed pilot documentation project is the collection and - partial - annotation of a variety of selected data types at a number of different levels, centring on the digital speech signal. The physical speech signal forms the basis of all field work, of course, in that it is perceived and analysed, with or without physical electronic recording, by the field linguist. However, very few physical speech signal data corpora are available for minority and, in particular, endangered languages, even in comparison with the small amounts of transcribed or other textual data. For this reason speech data collected in the proposed project will therefore be labelled, at a fine (at least syllabic) level of granularity.
We define a labelled signal representation as a time domain signal representation paired with a set of symbol-based representations, each of which is time-stamped with sub-intervals of the signal time domain interval. The standards identified in Gibbon, Moore & Winski 1997 will be adopted as far as possible. A labelled signal representation is a special case of aligned data streams.
This strategy has solid practical and theoretical reasons. The practical reason is that physical speech signal data are the linguistically most inter-theoretical or least theory-specific data conceivable - modulo the obvious proviso that they are based on theories of the physical world of acoustic signals (provided that due care and attention is given to ecological issues of corpus design and collation - Gibbon, Moore & Winski 1997, Part I). The theoretical reason is that physical signal data form an obvious point of comparison, tertium comparationis, for time-stamped symbolic data annotations at all other levels.
We propose a general methodological principle which we term the Data Matching Principle, and plan the design and creation of a model document set based on this principle:
|
Data Matching Principle (DMP): Data representations of the same speech signal as a physical event with temporal extent and a particular location are mapped both to the signal and to each other. |
Informally, the principle (once stated) seems rather obvious. Both formally and operationally in practice, however, the principle is far from easy to fulfil. We illustrate the principle and elaborate relevant details in the following discussion.
Starting with the DMP we define a data matching procedure as the procedure of comparing data reached by different methodologies. Examples of data matching in this sense are:
creation of interlinear translations, glosses, and morphological classifications;
merging of different types of lexical information in the microstructure of a dictionary;
tagging (markup) of texts and transcriptions with part of speech (POS), morphological, semantic etc. category names;
assignment of parallel markup to the same text;
signal annotation with phonemic, orthographic, or other symbolic labels;
temporal alignment of parallel audio, video, laryngographic, airflow signal sources.
It can be seen that the concept of data matching is a generalisation of a variety of existing attempts to provide multi-level (multi-tier) annotations of data. Many tools (documented by the LDC at http://morph.ldc.upenn.edu/annotation/) have been developed for dealing with this kind of representation activity, most rather ad hoc, some more systematic and based on explicit SGML or XML document type definitions (DTD). It stands to reason that while ad hoc procedures and tools appear to provide a maximum of flexibility, in fact they lead to a situation in which results of analyses are apparently incomparable in theory or in practice, and may remain hopelessly so. Consequences in practice are absurd situations such as those in which a given local language is provided with alphabetisation materials in different orthographies produced by initiatives which are either explicit rivals (whether theoretically, politically or religiously motivated) or are unaware of each others' existence. The demonstration of comparability of analyses, and provision of easily applicable comparison criteria, is not only a prerequisite for scientific work but also for practical, operationalisable working procedures and applications.
The DMP has a number of implications which need to be addressed in a documentation project such as the one proposed here:
representation: which abstract data structures are adequate for expressing both physical and linguistic properties of language data?
formalisation: how can such abstract data structures be related to existing transcription and markup conventions?
Recent work by Bird & Liberman (1999a, 1999b) has indicated that there is an exact formal answer to these questions, in the form of annotation graph data structure, for which they give a formal syntactic specification, and examples of how existing conventions translate into this more abstract specification.
However, a problem remains which is not directly addressed by Bird and Liberman: the semantics of such annotation graphs, i.e. the interpretation in terms of different empirical data sorts and different descriptive-theoretical assumptions. It is this question which is addressed by the more general idea of a data matching procedure which, in rather abstract terms, has the following components:
formal syntactic specification of a common least general format for all representations (of the kind developed by Bird and Liberman);
denotational semantic specification of 'possible annotation worlds' in terms of elementary (transcription) symbols, category sets, and of relations between these worlds (granularity, generalisation/specialisation, part/whole, dimensionality, etc.);
procedural semantic specification of the derivation of particular transcriptions from general representations (e.g. the automatic derivation of optimised autosegmental representations - and therefore annotation graph structures - from underlying segmental phonological representstions, Carson-Berndsen 1998);
reduplicable operational empirical procedures for creating representations of given data.
In logical terms, then, the DMP is the empirical principle which underlies correspondence theories of truth for linguistic annotations. These prima facie somewhat abstract considerations are emphatically not in competition with empirical, pragmatic approaches to linguistic description, and are most certainly not a 'formal corset' for constraining the voluminous undulations of empirical variety. They are simply design considerations for shared resources, and assume that shared resources are a desirable part of scientific and practical activity.
That said, formal considerations of course fall into the remit of the database and software development project described in the Foundation's Call for Proposals. However, we consider that it would be a mistake not to address issues of this kind from the outset in the model documentation projects themselves.
In summary, the special features of documentation in the current project proposal are:
emphasis on (stereo) physical speech signal recordings of the highest possible quality;
emphasis on well-planned corpora;
explicit consideration of the Data Matching Principle in corpus planning and creation.
production of multi-tier annotations of physical speech signal recordings with the aid of suitable acquisition and analysis tools;
production of fine-grained phonetic data for multi-tier analysis (e.g. acoustic signal, laryngograph, airflow).
Good contacts have already been established with the Ega speaker community via a female Dida speaker with personal contacts in Ega country, a student at U Cocody, Abidjan, who has just finished an M.A. thesis on aspects of Ega phonology. In Summer 1999, Connell and Ahoua, who are involved in the preparation of the present proposal, personally financed preparatory fieldwork on Ega, and produced digital audio and video tapes which will be used in the project.
The cooperating colleagues in the host country are affiliated to Département de Linguistique / Institut de Linguistique Appliquée, Université de Cocody, Abidjan, Côte d'Ivoire. U Bielefeld has an official cooperation agreement in the area of language documentation with U Cocody and has run various exchanges, guest seminars, Humbolt Fellowships and DAAD (cf. also CVs of Dafydd Gibbon, Firmin Ahoua).
In addition to U Abidjan, continuous exchange and cooperation takes place with a number of institutions thoughout the world on language documentation in general, and on minority and endangered languages. The main institutions concerned are listed in Annex A.
We are fortunate in having obtained the agreement of Dr Bruce Connell, U Oxford, to act as project scientist for the duration of the project, should the project be funded. With Frmin Ahoua, Dr Connell and I have worked together on a number of pertinent issues in the Ivory Coast. The time-consuming nature of the documentation work requires the full-time involvement of a very experienced colleague.
The roles and tasks of the main participants in the project are detailed in the following Table.
|
Role |
Name |
Task |
|
Initiator |
Prof. Dafydd Gibbon |
Coordination; document and multi-tier annotation graph specifications; phonology, tonology, lexicology; report and evaluation. |
|
Project scientist |
|
Fieldwork planning and supervision, audio and video data collection, phonetic analysis; video and audio data archiving. |
|
External project scientist |
|
Liaison with speaker community and language planners (ministry); genetic affiliation wrt Kwa group, typological comparison, fieldwork, phonetic and phonological analysis, local digital data processing and data transfer. |
|
Consultant |
|
Administrative coordinator (fieldwork logistics, preparation of student helpers, organisation of computional support). |
|
Consultant |
|
Liaison with language planning authorities on orthography standardisation; consultation on French contact language situation and French scientific community; syntactic and morphological analysis. |
|
Consultant |
|
Liaison with Dida (Kru) regional authorities, linguistic situation of Dida and of langauges. |
|
Technical consultant |
|
Local support for hardware installation and repair, software installation and maintenance, networking (incl. Internet). |
|
Student assistants |
|
Phonetic annotation, phonemic analysis, morphemic analysis, syntactic analysis. |
|
Language assistants |
Members of the Ega speaker community |
Speech production (questionnaire, selected discourse types); ethnographic information. |
The Institut de Linguistique Appliquée has the official mandate for fieldwork in Côte d'Ivoire, and by virtue of the official cooperation agreement between the U Cocody, Abidjan, and U Bielefeld, ILA procures the requisite permission for operating in the regions of interest. This has already taken place. As outlined above, the necessary informal contacts have also already been acquired.
The preliminary activities are such that work can start immediately on approval. In particular, preliminary negotiations with potential project participants and U Cocody have been successfully concluded, and the agreement of the partners listed in Annex A to cooperation on specific aspects of the project has been acquired. The infrastructure for multimedia linguistic documentation, including training facilities, is in place at U Bielefeld, and can be efficiently installed in Abidjan practically immediately after the project starts.
The status of our own research and development in the area of language documentation has been implicitly discussed in the above descriptions in the direct context of the description of project goals and methodology, and is characterised in the Cvs of the main participants. We will outline the relevant areas of current research, and then detail the relation to our own work.
Awareness of the endangered languages issue has been growing for many years, and there are well-established groups in Australia, Japan, South Africa and the United States which are very active in this area. In Europe, professional bodies such as the Foundation for Endangered Languages in the UK, the Gesellschaft für bedrohte Sprachen in Germany, the working group Bedrohte Sprachen of the Deutsche Gesellschaft für Sprachwissenschaft, and the recently established Special Interest Group Speech and Language Technologies for Minority Languages (SALTMIL) of the International Speech Communication Association (ISCA) are actively working on the problem. Semi-commercial speech and language data dissemination agencies such as LDC (Linguistic Data Consortium, U Pennsylvania) and ELRA/ELDA (European Language Resource Association / European Language resource Dissemination Association) have also committed themselves to this issue. The Session on minority languages at the Language Resource and Evaluation Conference (LREC 1998) in Granada, chaired by the present proposer, was well attended, and the coming LREC 2000 conference in Athens will also host a Workshop on Endangered Languages. For the first time, a Workshop on the topic is planned at the 2000 Biennial Conference of the West African Linguistics Society / Société de Linguistique de l'Afrique de l'Ouest. In January 2000 a workshop on technological support of language documentation is being hosted by the Linguistic Society of America at its annual meeting.
In Germany, the emergency situation with respect to the need to saving endangered languages was brought to the attention of a larger linguistic public in a report by a group of scholars in 1992. The report constituted a decisive innovation from the anthropological, ethnological and linguistic points of view, while drawing from the best German documentary and descriptive traditions of the nineteenth century. In the report, the need for projects on the documentation of endangered languages, and the topic of language extinction were raised up as one of the serious world wide, cultural and human challenges of the coming millenium. Fortunately publishing houses such as Mouton de Gruyter and Köppe Verlag have become involved in furthering the issue; publications during the 1990s (e.g. cf. Brenzinger 1992, 1998) have contributed both to establishing the issue as a serious topic for cross-disciplinary research for linguists, ethnographers and archeologists and as proof of the rapidity of the language death phenomenon and the urgency of the issue.
The study of endangered languages is not a young discipline, and the involvement of experienced researchers is essential at many levels: for resource planning, for work in the field, for linguistic and ethnographic analysis, and for consultation on the design of ergonomically usable computational tools. The proposers have extensive cooperation with colleagues in this area, and intend to work on building a consensus of `best field practice' in documenting the selected language. In the current proposal we would like to focus on the relevance of our work over the past two decades in the description of a range of European and African languages using techniques from the computational linguistics of spoken language. The relevant results can be itemised as follows:
formal models for tone patterns in West African languages;
phonetics of prosody, prosodic models;
AI oriented inheritance lexicon concepts for West African languages;
development of a general linguistic architecture (Integrated Lexicalism, ILEX) for
|
coordination of the Bielefeld-Abidjan documentation project and training of Ivorian staff and students in the deployment of speech and language technologies;
coordination of the Spoken Language Working Group of the European Commission funded EAGLES (Expert Advisory Groups for Language Engineering Systems) project on collating standards of best laboratory practice in speech technology (corpus processing and collection, lexicon construction, system evaluation);
chief editor of the following handbooks, the first on conventional spoken language systems, the second on dialogue and multimodal systems:
|
|
We plan to use available results from these projects, particularly the DAAD project, in creating the following kinds of documentation (see also deliverable list in Work Programme):
Basic questionaire as elaborated in preceding projects (see Appendix).
Outline of phonology and phonetics, the latter including spectrographic and F0 analyses and, where relevant, laryngograph and video recordings, and selected annotated audio data.
Grammar on accepted typological principles.
Semasiological dictionary in the form of a mutimedia lexical database with microstructure to be negotiated with partners (at least: phonemic, tonemic, local orthography/orthographies, gloss, related expressions, linguistic context, preliminary classification, audio examples, video examples where relevant, lexicographic notes.
Thesaurus of culture-specific word-fields.
Transcribed recordings of (oral) texts: such as tales, greetings, forms of address, dialogues, ceremonies, interlinearised with free translation by language assistant and close translation by linguist and as far as possible with other tiers.
Classified audio and video recordings.
Ancillary material: field notes, maps, etc.
The main support strategies for the documentation activities are:
Deployment of tools developed locally in previous projects in collaboration with the central software development project for:
Hypertext questionnaire conversion for data acquisition (interfaced to forms, CGI) and access.
Hyperlexicon construction (with multimodal information).
Concordance construction with text links.
Corpus transcription and annotation with standardised markup (in consultation with partners, probably XML, DSSSL).
Application of the general corpus design, collection and description standards collated in the Handbook of Standards and Resources for Spoken Language Systems (Gibbon, Moore & Winski 1997).
We would like to emphasize the need for standardisation of documentation, shared methodology, shared specifications of non-proprietary, platform-independent software and hardware, and therefore for involvement of the pilot projects in professional software development procedures.
Based on previous experience of the coordination of project consortia at the German national level (Verbmobil lexicon subprojects), European level (EAGLES Spoken Language Working Group) and international level (Encyclopédie des Langues et Cultures de Côte d'Ivoire, DAAD), it is planned to establish a local database-driven internet telecooperation site on the model of the mSQL-based EAGLES Spoken Language Working Group site:
http://coral.lili.uni-bielefeld.de/EAGLES/SLWG/
The initial requirements specification of the site is:
Electronic archive for field notes, raw digital material (audio, video), questionnaire results, linguistic analyses, reports.
Bulletin board for project communications with international partners.
Chat facility for low cost teleconferencing.
Contact address database.
Since a model for the site exists already, the site can be constructed at insignificant extra effort. At the termination of the project, the archive will be donated to the library of the Département de Linguistique and the Institut de Linguistique Appliquée, Université de Cocody, Abidjan, on condition that it also be available for central archiving within the terms of the VW Documentation of Endangered Languages funding programme.
In addition to the database-driven site, we are currently developing an automatically generated hypertext style of questionnaire web presentation which can serve as a source of functional specifications for an XML/SGML DTD driven structure editor for systematic survey input. A sample from a development prototype is shown in the following screen shot.
Multifunctional documentation of data (Ega):
|
Questionnaire data: |
Based on a questionnaire already developed for other languages in the DAAD project "Encyclopédie des langues et peuples de Côte d'Ivoire" (Funding period: 1997-2000); s. Annexe. |
|
Audio data (DAT): |
Systematic sentence-framed examples for tonological, phonological, phonetic study, interviews, tales, village history - s. also video data. |
|
Laryngographic data (DAT): |
Low noise, high quality tone and discourse intonation study. |
|
Video data: |
Ceremonies, greetings, task-oriented dialogue (e.g. tool or musical instrument construction, cooking. |
|
Linguistically processed data: |
Transcriptions; signal selections annotated with selected tiers (phonememic; tonemic, morphemic) in ESPS and/or Praat formats. |
Prototype database structure specifications:
|
Prototype document type specifications and prototypes:
|
Evaluation proposals (evaluation workshop preparation):
|
Macrostructural data model (relational, object-oriented) and DBMS (Database Management System) selection and recommendation.
Microstructural interchange format recommendations:
|
Version control support.
Acquisition and linguistic processing tool: SGML/XML based structure editor for:
|
|
Dates |
Tasks |
|
M0-M3 |
|
|
M3-M6 |
|
|
M6-M9 |
|
|
M9-M12 |
|